最近更新时间:2022-03-31
大数据平台提供一体化的安装运维管理界面,通过Web界面化的方式实现一站式安装部署、监控告警、参数配置、服务管理、日志审计、用户管理、多集群管理等功能,避免用户在多个管理界面间切换;对集群的各项服务做集中式管理,提供启动服务、停止服务、修改属性和设定运行参数等功能,实现集群各项服务运行状态(基本信息、告警、运行健康状态)实时监控,保障集群稳定运行。UniCloud 大数据平台兼容主流X86服务器(Intel)以及ARM服务器(鲲鹏/飞腾等CPU),操作系统支持Centos、中标麒麟、银河麒麟等。
数据工厂覆盖数据采集、存储、计算、分析、开发、调度等环节的大数据全链路处理能力,降低用户使用大数据的门槛,帮助用户快速构建大数据处理体系。
文件管理为用户提供可视化的HDFS操作能力,免去了用户依靠终端输入命令行的方式进行HDFS操作,支持可视化上传、下载、共享等操作。
数据开发以拖拽方式构建任务流,按照时间和依赖关系的对进行任务调度管理,支持对Shell,Java,MapReduce,Spark,HDFS,Hive,SparkSQL等任务调度与编排。
连接管理支持SSH协议主机连接和大数据组件HDFS、Hive、SparkSQL、Impala、Phoenix数据源连接。
UniCloud BDP提供MapReduce、Spark和Flink三种分布式处理框架,分别满足稳定、高效、快速迭代三类应用场景,同时支持Hive、SparkSQL等SQL on Hadoop工具,简化计算任务编写过程,快速进行数据开发工作。
Hive默认执行引擎采用Tez计算框架,将多个具有依赖的作业转换为DAG作业,避免复杂任务多次读写HDFS过程,大幅提升作业运行性能,复杂计算场景下相比MapReduce作业能够提升10倍以上性能。
提供Spark内存计算框架,通过RDD之间的血缘关系管理算子之间依赖关系,确保数据能够快速恢复并重新计算,中间结果数据支持灵活选择内存、SSD等缓存模式,在迭代式计算场景提供更高性能的算力,计算性能可达MapReduce的10-100倍。
采用Flink计算框架统一流批处理,一个计算引擎可同时满足流计算业务和批处理业务,支持自实现状态管理和Exactly-Once语义,具有容错机制,保证数据零丢失,具有极佳的吞吐量及亚秒级延迟性能。同时支持完善Flink SQL语法,快速实现双流join、流批join等业务场景,降低流式作业开发难度 。
UniCloud 大数据平台提供自研DLH组件,对外提供统一的SQL访问服务。兼容通用标准SQL,从数据库平滑过渡到大数据平台,提升SQL兼容性,可对接ES、HBase、Hive等数据源,降低平台使用门槛;提供增强型统一SQL on Hadoop方案,支持图计算与机器学习SQL,大幅度提升平台易用性。
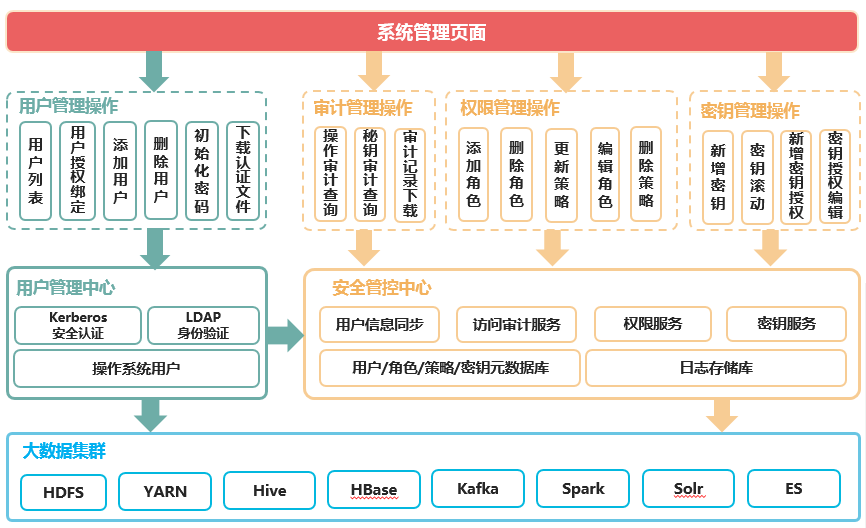
为保障用户的数据信息安全,UniCloud BDP集成了用户身份认证和权限管理功能,在创建大数据集群时根据实际需求进行启用安全管理即可。
开启安全管理的集群统一使用Kerberos认证协议进行安全认证,kerberos认证支持密码认证和keytab认证两种模式,集群管理员可在用户管理模块为集群使用者分配用户和设置认证密码,避免外部用户登录集群,提高集群安全性。
由于集群每个特定用户可能拥有集群资源的不同访问和使用权限,为保护不同业务数据的信息安全,安全集群利用Ranger进行鉴权,确保认证用户拥有集群资源的访问权限。如果用户权限不足,需要管理员为用户授予对应资源的权限后才能进行访问。
基于Hadoop 3.0版本,与开源社区的版本、接口保持一致,不采用私有架构。提供分布式文件存储、海量数据处理、实时数据分析、交互式查询、数据检索、安全认证与权限管理等功能。软件服务组成及功能描述如下:
服务名称 | 版本号 | 描述 |
YARN | 3.0.0 | Hadoop资源管理器,是一个通用的资源管理系统,可为上层应用提供统一的资源管理和调度服务,使MapReduce、Spark、Flink等多种计算框架共享资源 |
HDFS | 3.0.0 | Hadoop分布式文件系统,具有高容错、高吞吐等特点,适用于存储超大文件 |
MapReduce2 | 3.0.0 | 批处理框架,主要用于离线计算、计算密集型应用。设计思想是分而治之,即将一个大任务分成多个独立的小任务,最后汇总各个小任务的结果 |
ZooKeeper | 3.4.5 | 分布式应用程序协调服务,为集群提供一致性服务,包括配置维护、名字服务、分布式同步、组成员管理等 |
Spark | 2.4.0 | 一个快速的通用的大规模数据处理引擎,提供批处理、流处理、SQL查询、机器学习、图计算、R语言等功能。Spark计算中的中间结果缓存在内存中,在后续计算过程中直接读取缓存数据,具有高效的计算性能。 |
Storm | 1.2.1 | Storm是一个分布式的、容错的实时流处理引擎,效率非常高且能保证每条消息都能被处理 |
Tez | 0.9.0 | 一个支持DAG作业的计算框架。Tez将多个有依赖关系的作业转化为一个DAG作业,大幅提升性能,帮助MapReduce克服在迭代计算和交互式计算方面的不足 |
HBase | 2.1.0 | HBase是一个分布式、面向列的NOSQL数据库,常用于非结构化和半结构化数据的存储和查询。在应用程序开发中,常使用Java API等接口访问HBase中的数据,也可以借助Phoenix等SQL引擎使用JDBC访问HBase中的数据 |
Redis | 6.2.1 | Redis是Key-Value型内存数据库,支持单机和集群两种运行模式,常用作高速缓存和消息队列代理 |
Flink | 1.12.2 | Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎 |
ElasticSearch | 7.4.0 | ElasticSearch是一个基于Lucene的全文搜索服务器,提供了一个分布式的、多用户全文搜索引擎。对外提供RESTful编程接口,特点是易扩展、实时搜索、稳定可靠,是当前流行的企业级搜索引擎 |
Solr | 7.4.0 | Solr是一个基于Apache Lucene项目的搜索平台。其主要功能包括全文搜索、命中突出、面搜索、动态集群、数据库集成和丰富的文档(如Word、PDF)处理 |
Hive | 2.1.1 | 基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的类SQL查询功能,具有以下特点: 易于进行数据抽取、转换和加载 支持多样的数据存储格式 能直接访问存储在HDFS或其他的数据存储系统(如HBase)上的文件。多种使用方式,支持Shell交互式命令、JDBC、WebUI等 |
Impala | 3.2.0 | Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎,提供了高性能和低延迟查询分析能力。 |
Kafka | 2.3.0 | 一种高吞吐量的分布式发布订阅消息系统 |
Infra Solr | 0.1.0 | Infra Solr是一个专门提供给LogSearch服务的企业级搜索应用服务器 |
Sqoop | 1.4.7 | Sqoop是一个用于Hadoop和结构化数据存储(如关系型数据库)之间进行高效传输大批量数据的工具: Hadoop数据:HDFS文件、HBase表、Hive表 关系型数据库:MySQL、PostgreSQL、Oracle、SQL Server和DB2等支持JDBC的数据库 |
Kerberos | 1.10.3.10 | Kerberos是一种不依赖主机地址信任、不要求网络中所有主机的安全,通过密钥系统为客户机和服务器应用程序提供强大的认证服务的网络认证协议 在Hadoop中,使用Kerberos来安全访问各个服务 |
HBase Indexer | 1.5 | HBase Indexer是针对HBase开发的索引插件,使HBase支持二级索引 |
Oozie | 5.1.0 | Oozie是用于Hadoop平台的工作流调度引擎,管理Hadoop作业 |
Flume | 1.9.0 | Flume是一个分布式的、高可靠的、高可用的将大批量的不同数据源的日志数据收集、聚合、移动到HDFS进行存储的系统 |
DLH | 1.0.0 | 基于Hive的数据湖仓库服务,融合批处理、交互式及流处理,具备数据协同分析能力 |
