最近更新时间:2022-03-31
UniCloud BDP提供可视化的集群安装部署界面,方便快捷的进行资源管理,主机分配等操作,支持组件服务一键安装、升级和图形化运维,实时监测各项服务的健康状态以及运行指标,超过一定配置阈值后进行告警并邮件通知管理员,大幅提升运维效率。
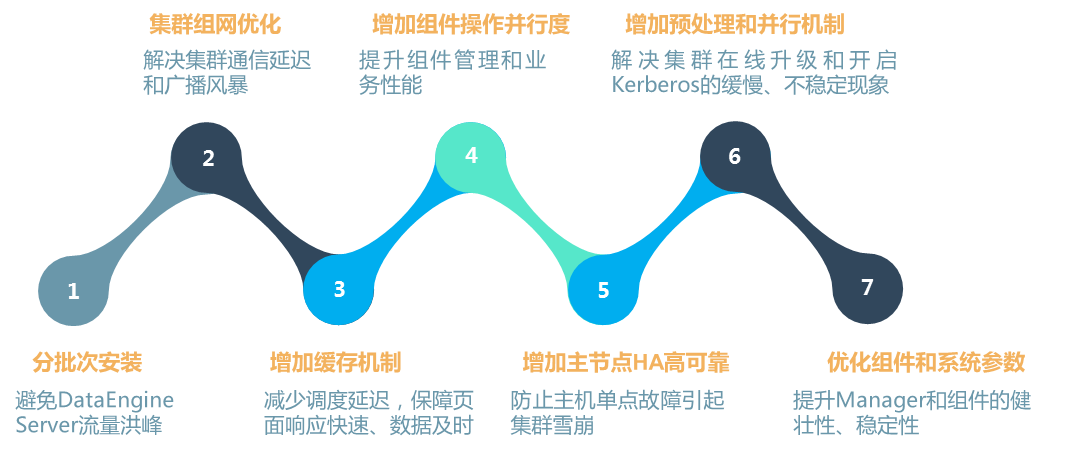
UniCloud 大数据平台深度优化集群扩展能力,支持2000+节点以上超大规模集群的实施能力,具备丰富的大规模集群调优能力,从规划部署策略,反复验证以更少的资源实现更大资源合理利用、优化部署架构,实现分片并行、增加本地化安装源避免流量洪峰、修改单线操作,合理提高并行度,提升组件管理和业务性能、增加缓存机制,减少调度延迟,保障页面响应快速,数据更新及时、反复优化组件资源参数和系统参数,提升大集群稳定性。
数据工厂中支持可视化的工作流任务编排,并提供强大的工作流调度引擎。用户可以调试运行工作流,也可以周期运行工作流。在周期调度设置中,支持多维度的调度方式,即可以按照年、月、周、日、小时、分钟的方式进行工作流执行周期的设置。同时支持工作流的优先级与并发数设置,用户可以针对不同工作流设置不同的优先级,或者针对工作流实际运行需求来设置并发数。
为应对云原生大数据发展趋势,解决传统存储和计算一体化的大数据集群存在资源利用率低、资源扩容不灵活等问题,E-MapReduce支持存算分离架构,扩展原生Hadoop能力,支持对接对象存储,存储和计算资源灵活配置,根据业务需要各自独立进行弹性扩展,使得大数据集群资源利用率大幅提升。
E-MapReduce存算分离完全兼容HDFS读写接口以及原生权限管理模型,上层业务无感知,同时充分利用对象存储的高带宽、高并发特点,对数据访问效率和并行计算进行深度优化,相比原生HDFS,存算分离写性能提升20%左右,读性能相当。
支持R语言,集成机器学习算法库Spark MLlib,包含聚类分析、分类算法、频度关联分析和推荐系统在内的常用机器学习算法。满足批处理统计分析、在线数据检索、R语言数据挖掘、实时流处理、全文搜索等全方位需求。可帮助企业建立高速可扩展的数据仓库和数据集市,结合多种报表工具提供交互式数据分析、即时报表和BI可视化展示能力。
UniCloud BDP基于安全协议Kerberos实现安全认证,使用LDAP作为账户管理系统;同时利用Ranger提供统一的用户和角色的管理体系,遵从RBAC(Role-Based Access Control)模型规范,通过角色绑定用户进行权限管理。此外UniCloud BDP还支持用户对各组件的审计日志及检索能力,全组件管理界面均支持单点登录,使得平台真正做到安全可靠。
提供统一SQL服务和可编程API,提取数据存储计算平台的数据处理结果,屏蔽底层细节,为上层应用提供数据服务。数据服务接口主要包括SQL接口、MapReduce/Spark/Storm/Flink等多种计算框架的可编程API、全文搜索接口、业务定向接口、关联查询接口,满足数据查询、可视化BI展示、数据分析、综合查询等业务应用的需要。提供接口文档、二次开发指导手册与二次开发示例程序,满足开发人员的使用需求。
数据平台支持独立模式和共享模式两种资源划分模式,满足不同场景下业务需求。共享模式下可以创建一个大集群,不同用户申请集群的共享存储和计算资源,并通过权限进行隔离,适合对资源管控严格且各二级部门数据交换频繁的企业使用。独立模式下不同用户可申请创建单独的集群,独享集群的所有资源,不同集群之前使用网络进行隔离,适用于资源比较充分且各二级部门之间业务相对独立的企业。
此外为满足企业稳定性要求,UniCloud BDP还提供了常用服务的独立产品模式,包括NoSQL数据库HBase、内存数据库Redis、消息中间件Kafka、搜索服务Solr和Elasticsearch,避免不同组件之间资源抢占影响集群稳定性。
